جلسه دفاع پایان نامه: رامتین تولی پور، گروه سیستم های اقتصادی و اجتماعی
خلاصه خبر:
عنوان پايان نامه: حل مسئله مسيريابي وسايل نقليه الكتريكي با انبار هاي چندگانه و سياست تعويض باتري به كمك رويكرد يادگيري تقويتي
ارائه کننده: رامتین تولی پور استاد راهنما: دكتر سيد احسان سيد ابريشمي استاد راهنماي دوم : دكتر احسان نيك بخش استاد داور داخلي: دكتر علي حسين زاده كاشان استاد داور خارج از دانشگاه: دكتر سيد محمود مصباح نميني نماينده تحصيلات تكميلي: دكتر علي حسين زاده كاشان تاریخ: 1404/03/04 ساعت: 12:30 مكان: اتاق سمينار طبقه منفي يك دانشكده فني و مهندسي
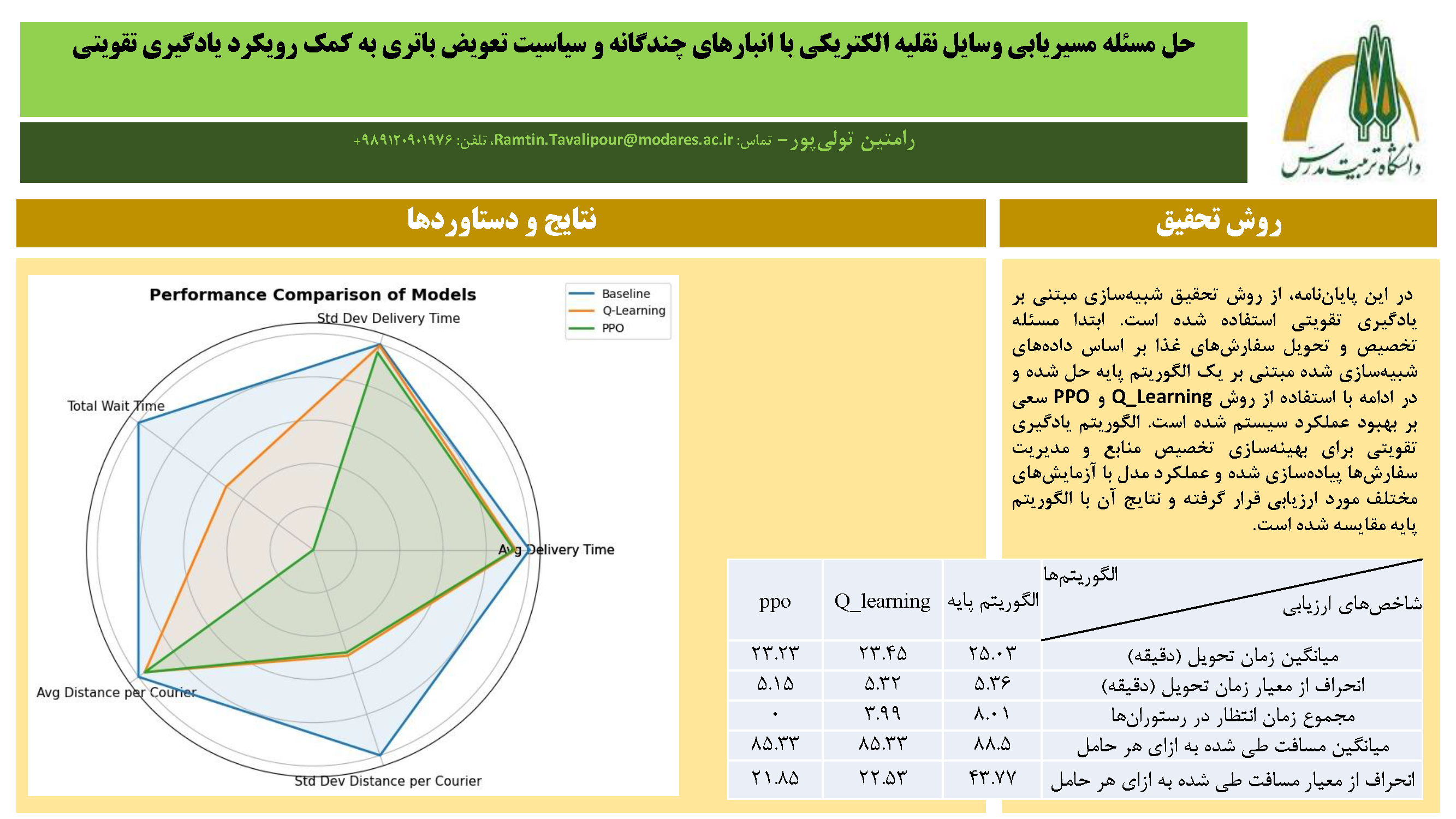
چکیده: در سالهای اخیر، با گسترش استفاده از پلتفرمهای سفارش آنلاین غذا، طراحی سیستمهای هوشمند برای بهینهسازی فرآیند تحویل به یکی از چالشهای مهم در حوزه لجستیک شهری تبدیل شده است. هدف این پژوهش، ارائه و ارزیابی یک چارچوب تصمیمگیری مبتنی بر یادگیری تقویتی برای تخصیص بهینه حاملها به سفارشهای گروهبندیشده در محیطی شبهواقعی است. در این راستا، یک محیط شبیهسازیشده طراحی شد که در آن متغیرهایی نظیر مکان مشتریان، زمان آمادهسازی غذا، ایستگاههای تعویض باتری، و محدودیتهای حرکتی در شبکه گریدی مدلسازی شدند. در فاز نخست، یک الگوریتم پایه مبتنی بر اختصاص نزدیکترین حامل به مرکز خوشه پیادهسازی شد و به عنوان معیار مقایسه مورد استفاده قرار گرفت. سپس الگوریتم Q-Learning برای بهینهسازی تصمیمگیری در فاز تخصیص توسعه داده شد. نسخه اولیه این الگوریتم، با وجود عملکرد قابل قبول، بهبود محدودی در شاخصها داشت؛ اما نسخه دوم آن، با تعریف پیچیدهتر وضعیت، روند یادگیری مؤثرتری از خود نشان داد. در گام بعدی، الگوریتم پیشرفته Proximal Policy Optimization (PPO) بر پایه ساختار Actor-Critic پیادهسازی گردید و با بهرهگیری از شبکه عصبی توانست عملکرد پایدارتری نسبت به Q-Learning ارائه دهد. در بخش ارزیابی، الگوریتمها از نظر شاخصهایی نظیر میانگین زمان تحویل، انحراف معیار زمان، مجموع زمان انتظار، و یکنواختی مسافت طیشده مورد مقایسه قرار گرفتند. همچنین، بهمنظور تحلیل پایداری مدل، تحلیل حساسیت نسبت به پارامترهایی مانند تعداد حاملها، مقدار K در خوشهبندی، و بازه زمانی گروهبندی سفارشها انجام شد. نتایج نشان داد که الگوریتم PPO در اکثر شاخصها عملکرد بهتری نسبت به روش پایه و Q-Learning دارد و در عین حال در شرایط کاهش منابع نیز از انعطافپذیری قابل قبولی برخوردار است. قابل ذکر است مدل نهایی استفاده شده در این پژوهش توانسته شاخصهای ارزیابی عملکرد میانگین زمان تحویل، انحراف از معیار زمان تحویل، میانگین مسافت طی شده به ازای هر حامل و انحراف از معیار مسافت طی شده به ازای هر حامل را به ترتیب 7.2%، 3.9%، 3.6% و 50.1% بهبود دهد. همچنین شاخص ارزیابی مجموع میزان انتظار حاملها در رستورانها جهت جمعآوری سفارشها را به صفر برساند. در پایان، با بررسی محدودیتهای موجود، پیشنهادهایی برای توسعههای آتی از جمله استفاده از یادگیری تقویتی در فازهای گروهبندی و مسیریابی، بهرهگیری از دادههای واقعی، و افزودن عدم قطعیت به مدل ارائه شده است. این پژوهش نشان میدهد که ترکیب الگوریتمهای یادگیری تقویتی با راهبردهای گروهبندی، میتواند راهحلی کارآمد برای مدیریت بهینه سیستمهای تحویل در مقیاس شهری ارائه دهد.